


Social Preferability: Adding a layer of 'inclusivity' to ethical decision-making
Here's a brief description of how Social Preferability Research practices can augment ethical decision-making systems within complex organisations.

Down under, we have a saying that basically equates to, “I’m not here to mess around. Let’s do this!”
I’ll let Margot Robbie explain (toward the end of this short clip).
With that out of the way, let’s dive in.
In this context, ‘social preferability’ refers to an empirical body of evidence that demonstrates the support - or lack thereof - that an organisation’s key stakeholder groups (customers, independent advocacy groups, regulators, staff, shareholders etc.) assign to both the intent and likely outcomes of a given initiative or business activity.
Social Preferability is ‘scored’ using a combination of qualitative and quantitative measures (the result of a mixed method research program in most cases). The scoring system can be very simple, typically relying on 1 - 7 likert scale questions embedded at specific junctures in the participant experience.
This approach is generally about ‘socialising ethics’ and making the process both inclusive and additionally empirical. As I’ve recently discussed, this, and many other approaches, hold promise for various application areas, including Generative AI. It is one of many tools that an organisation might call on as they engage in workflows supported by their ‘system’ for ethical decision-making.
The evidence gathered during this mixed method research program serves the purpose of enhancing the confidence with which ethical decisions can be made (based on more diverse and inclusive inputs from the people that will be directly and indirectly impacted), yet also supports the organisation in proactively communicating and/or defending ethical decisions (say, if their key decision log, of a version of it, is made public as part of a commitment to openness) and tradeoffs in various contexts (let’s keep in mind, even the most robust moral analysis will eventually encounter difficulty, uncertainty and surprise. The system for ethical decision-making caters to this, supporting proactive, retroactive and retrospective decision-making contexts).
This last point about ‘defending’ is important given the ‘risk based’ nature of most ethical decision-making contexts within corporations and governments.
The net result, framed from the organisations perspective, is that the organisation decreases ethical uncertainty (enabling more confident action). From the perspective of those who might be impacted by a given product or service, the net result ought to be a greater confidence in the integrity of the process (this gets into evidence of organisational trustworthiness and other stuff I’ve written extensively about).
That’s the basic context.
Conducting Social Preferability Research.
As described in a previous post, this type of approach to more diverse and inclusive ethical decision-making leans on a series of (non-exhaustive) assumptions / beliefs, like:
We have a deep ethical responsibility to the ecosystem within which we operate
To some extent, ethics is actually everyone's job
Doing ethics can make us better at what we do. It can help us responsibly innovate
The challenging ethical decisions we are trying to make can’t be made by us and us alone. We are not the arbiters of moral truth
The most grounded and considered ethical decisions are made when the people impacted by said decisions are involved in the process
As this video highlights, when these beliefs are present, this can become a prominent tool and process that organisations can call upon.
Here’s an overview of the whole system in action.
Decision-making processes within an ethical decision-making system can be:
Proactive as part of doing something new or making a change (this is most likely the context within which Consequence Scanning will prominently feature)
Reactive as part of a triggering event that requires a more formal process to be undertaken
Proactive as part everyday work (issue backlog grooming workflow etc.)
Retrospective or retroactive as part of a variety of potential workflows the system describes
The general sequence is (proactive example here):
Something new is identified. This can be a new initiative (i.e.e we want to build X) or an ‘ethical issue’ (something identified that requires attention)
The parties responsible for the decision-making process review existing evidence in the form of the Key Decision Log (have we explored an issue like this in the past?) and Knowledgebase (what theories might help us?). This acts to both speed up, and ensure consistency of ethically oriented decisions
If there is clear precedent, the decision will be made (or, depending on structure, advice will be give, which might lead to a business decision), added to the Key Decision Log and used to inform future business activities
If significant uncertainty remains, with answers not found in existing resources, additional work is done
If the core team is party to the decision, the next step is likely an internal process using a decision-making template (Consequence Scanning can be one of them). This template will draw on fit for purpose decision making tools (defined in the Knowledgebase and Toolkit)
5.1 A tool will be selected to support the decision. If decision clarity emerges from this structured process (say Consequence Scanning combined with a principles assessment), the decision is logged in the Key Decision Log. Evidence of the process accompanies the decision and anything new and/or useful is added to the Knowledgebase.
5.2 If decision clarity is not reached, the issue is added to the Issue Backlog.
If the core team is not party to the decision, the issue might be flagged (based on weightings, consistent criteria etc.) for review by the core team as part of their everyday workflows (this might be a team comprised with specific expertise, including moral analysis and applied ethics in the relevant context)
As part of the core team’s everyday workflows, backlog grooming helps prioritise unresolved issues
Unresolved issues given priority can be flagged for Social Preferability Experiments (or other ‘augmenting’ workflows)
Social Preferability Experiments are then defined, which forms a clear picture of the requirements (work to be done, type of cohort that needs to be recruited for participation, pass/fail parameters etc.)
The Social Preferability Experiments are then conducted
The results are analysed
11.1 If the result is a pass, the issue is resolved, the decision is logged and the data from the experiment is added to both the Key Decision Log and Knowledgebase
11.2 If the result is a fail, the issue circulates back through the same issue grooming process and will likely inform another experiment (unless this is expedited due to the issue remaining a priority. If this is the case, the learnings from the previous SPE can inform another SPE, which then follows the same process in terms of design, recruitment, running, analysis etc.)
The decision that’s been inclusively made and logged to the key decision log informs specific future actions
Then the cycle repeats, continuously, forever…
That gives you the context. Social Preferability is part of a much broader approach to ethical decision making.
Here’s a little explanatory content describing the process of social preferability (as a simple, mixed method research program).
We always start with a use case, usage context, or proposal to do something new. For example purposes only, let’s propose that we want to deploy a new machine learning model (perhaps something to do with servicing customers, but the detail doesn’t mater much for illustrative purposes) that has some distinct customer value proposition associated with it.
At the time of designing this experiment and proposing this new activity, we don’t have explicit permission from customers to use personal data (let’s say per the EU definition / scope) for this data processing purpose (of course, we practice the purpose specification and limitation principle). Therefore this is a new activity that extends the scope of data we would like to lawfully / justifiably, valuably and (relatively) safely process.
To make this slightly more concrete, let’s say the specific model is being proposed because one team within the business believes it will deliver direct value to customers (save them time, enhance the quality of the experience etc.) and create operational efficiencies for the business (decrease total number of service requests/calls, decrease the average time per call, enhance the quality of the service offering, which may result in a greater propensity for customers to refer/advocate etc.).
There are two key areas of focus for this experiment:
This first is that we need customers to give their explicit permission (maybe based on the lawful basis of ‘consent’, but this is a whole can of worms that I won’t get into right now) to use the data from their support requests to train (and potentially deploy) a new machine learning model (obviously there are various ways this could be done. Keeping it simple for now).
The second is that we need to show the outcome this new data processing activity might enable for them (this is about value appropriation, an important ‘rational’ consideration for people when considering whether the benefits of data sharing outweigh the various risks. This itself is a complex space I’ve studied and contributed significantly to over the past decade. More another time).
To do this we choose to develop a basic prototype of the permission flow. The experience we design clearly articulates the why, what, and how of this new data processing activity.

Example flow only. Heaps on consent UX here.
This provides a far more specific overview of how this research can be conducted (using consent in financial services as an example).
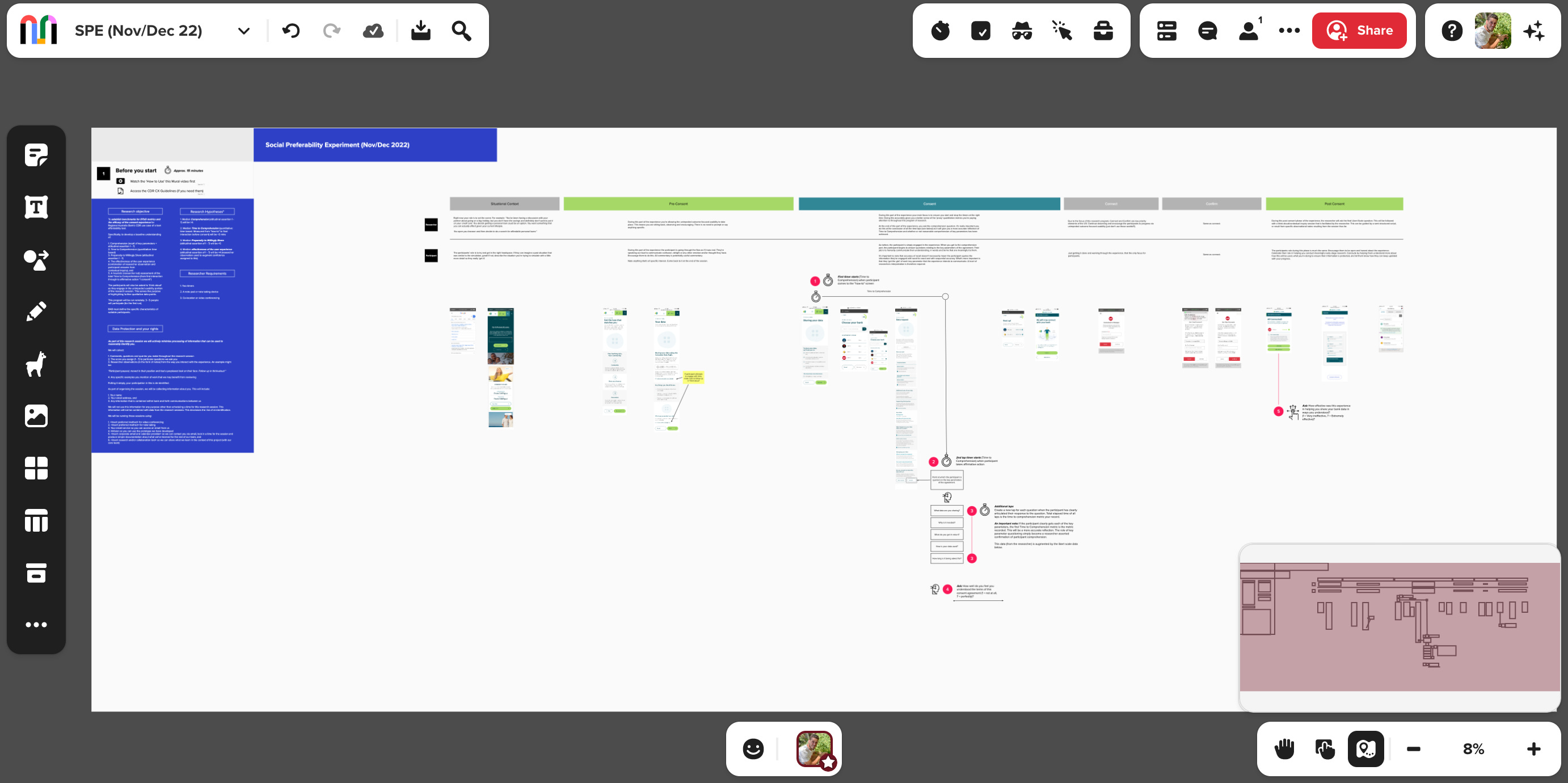
We also build the desired outcome (what people get out of the experience) into the prototype (this might be a wizard of oz type thing, or could simply be explained by the lead researcher).
This enables research participants to better understand the impact of what we are proposing to do. We do this because social preferability testing seeks to understand the support key stakeholders have for both the intent and outcomes of data processing activities. This dual approach helps us develop a richer picture of the attitudes, beliefs, preferences and potential behaviours that relate to the new thing we are considering doing.
Once we have the prototype, we design, recruit for, and run a tight research program. We refer to this as outcome-focused usability paired with contextual inquiry. It’s a hybrid research method that helps to gather proxy quantitative data by simulating real-life usage (effectively in a lab setting, which can of course be virtual. I’ve done this plenty of times over the last few years).

These metrics are then supported by qualitative and attitudinal data as a result of the researcher-led contextual inquiry.
Perhaps the most practical approach here is to embed Likert Scale questions (as mentioned above) at different stages of the research participants’ experience. In the case of our example, a useful place for a Likert Scale question is directly after a participant takes an action to grant permission (or not). Another might be a series of questions relating to certain values (i.e. agency / autonomy, fairness, the utility of the offering etc.). This sounds crude, but overall this is really about assessing, from the participants experience, the ‘ethicalness’ of the proposal (how it works, the likely outcome etc. Then, with additional explanations around model parameters, privacy and security practices etc. how participants feel - their level of support - for what is actually going on under the hood).
The framing of the prompting questions are also important. If we’re engaging other stakeholder groups like internal team members from legal or compliance, it’s important they approach this research session from a customer’s (or whoever the key audience may be) perspective (they will of course have unique insights to offer. but we often ask them to take their work hat off and try ‘embody’ the experience. We use lots of different tactics to do this. For distance, I once ran a program like this for VISA and we actually simulate the whole process of walking to an ATM to get money out etc. Your work in this space doesn’t have to be elaborate, but the more descriptive the context setting the better).
The same would be needed if we engage regulators in this research. We expect these stakeholders to contribute their professional perspective, but it’s as, if not more, important that they have genuine compassion (and potentially some empathy) for the individuals and groups the proposition seeks to serve.
Additional qualitative data (the answers to open ended questions) from the sessions can be used in the analysis stages to put the self-asserted scores in context (this free form content helps us better understand why people believe what they believe, act the way they do etc.).
In the simplex scenario, we’re measuring a single dimension where 1 = socially unacceptable, 4 = socially acceptable and 7 = socially preferable (you could do this one time with a well frame question, of this could be the result of a number of questions added up, divided etc. to get an average).
Over time you may choose to explore the use of social value orientations (or another approach that adds rigour and nuance to measurement). However, for the purpose of building some foundational evidence to support ethical decision making, our approach is focused towards making SPEs easy and cost effective (in a relative sense).
All of this, as I’ve mentioned like a broken record, is embedded into the workflows of an ethical decision-making system.
I recognise this is but a taste. Let’s chat if you want to dive deeper.